Project Map
The ICESat-2 deployment of SlideRule has a lot of moving parts and it can be difficult for new users to know where to find the code and documentation they need. This document will provide a high level overview of the different components of SlideRule and their associated code repositories and documentation trees.
Component Organization
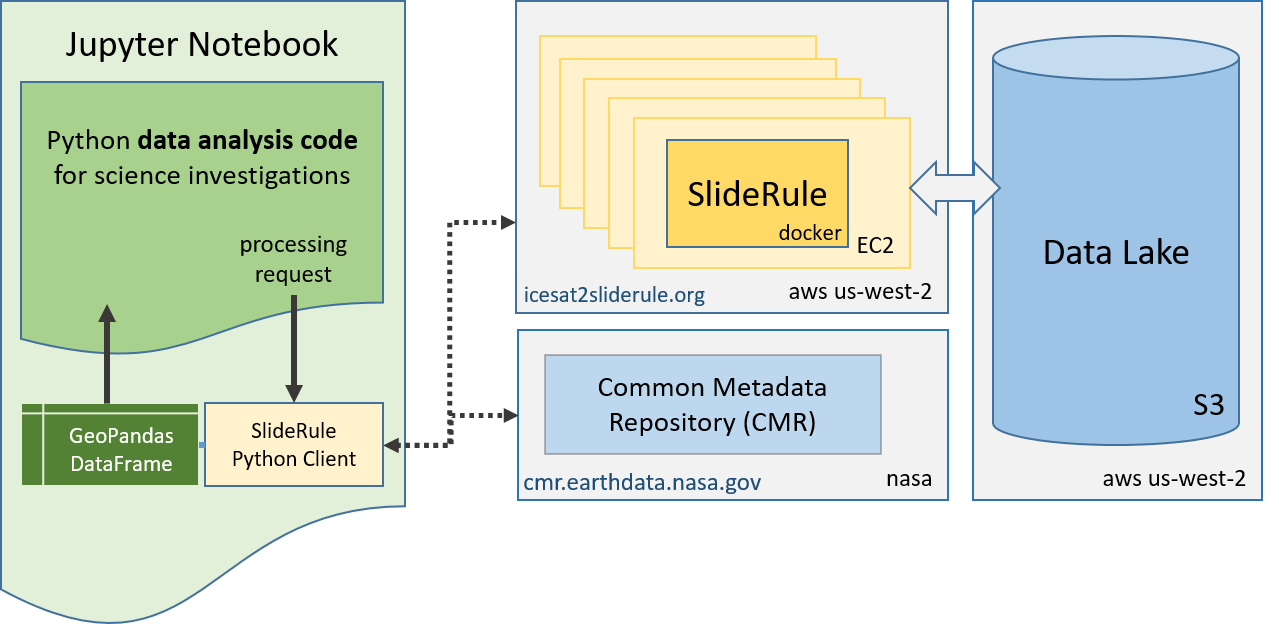
.
- Jupyter Notebook:
Jupyter Notebook|Lab|Hub is the expected analysis environment of researchers that want to incorporate SlideRule into their work. That doesn’t mean SlideRule can’t be used with other environments - it can; it works with any system that can issue HTTP requests and process HTTP responses. But the SlideRule project provides a Python client that makes it much easier to work with SlideRule, and on top of that, we’ve provided Python routines and examples that are designed to run in a Python Jupyter environment.
.
- SlideRule Python Client:
The SlideRule Python client is a set Python modules that provide functions for making processing requests to SlideRule web services. In a Jupter environment, all interactions with SlideRule occur through the Python client. For researchers that want to use SlideRule, the Python client is likely the only part of the SlideRule system they need to know.
.
- CMR:
SlideRule leverages NASA’s Common Metadata Repository (CMR) for querying which dataset resources (i.e. granules) need to be processed for a given processing request. When analysis scripts call SlideRule’s Python client functions and pass in time ranges and polygons that define geospatial regions, those functions typically will issue a request to CMR behind the scenes, passing through those parameters, to get a list of granules that match the criteria.
.
- SlideRule:
The heart of the SlideRule system is a cluster of EC2 instances in AWS us-west-2 running Docker containers of SlideRule’s server-side code. Earth science researchers do not need to know anything about how the server-side code works in order to use SlideRule. But for developers who are interested in how the server side works, SlideRule is a framework implemented in C++/Lua consisting of a core multithreaded data processing system, and extension packages that include things like the HTTP web server, the HDF5 data access library, and the mission specific algorithms.
.
- Data Lake:
SlideRule expects the source datasets it processes to be in different formats and hosted on different platforms. For ICESat-2, the three primary datasets used by SlideRule are in the HDF5 format and are hosted by the National Snow and Ice Data Center (NSIDC) in AWS’s S3 in the us-west-2 region. For those datasets, SlideRule takes care of Earthdata authentication and S3 interfacing, and makes it so that users do not need to worry about how the data is accessed.
Links to Project Resources
Example Jupyter Notebooks: sliderule-python/examples
Juypter Notebook Widgets: ipysliderule.py
Python Client Installation Instructions: Getting Started Guide
Python Client ICESat-2 API Reference: ICESat-2 Reference Documentation
ICESat-2 Data Processing User’s Guide: User Documentation
Additional Information on CMR: CMR Website
SlideRule Server Source Code: SlideRule GitHub
SlideRule Core Python API Reference: SlideRule Reference Documentation
Repository Organization
All of the software for SlideRule is open source under the BSD 3-clause license and developed in the open on GitHub. Users and future contributors are encouraged to browse the code, fork the repositories and submit pull requests, open issues, and post discussion topics.
The SlideRule project consists of one main repository with a few supporting repositories.
The sliderule repository includes all source code for the deployment of sliderule
server: mission agnostic C++/Lua framework for processing science data
plugins: mission specific plugins providing data subsetting and processing algorithms
python client: the Python client code that allows users to easily interact with SlideRule from the Python language
documentation: source for our static website and user documentation
infrastructure: infrastructure code which contains the scripts and definition files for deploying the SlideRule system to the AWS cloud
The sliderule-python repository includes example Jupyter notebooks for using SlideRule to perform common science data analysis workflows
The sliderule-prov-sys repository containing the source code for the SlideRule Provisioning System; written in Python/Django